
Melhorando os Modelos GPT com a Nova Abordagem para Modelos Autoregressivos

Recentemente, pesquisadores do Idiap Research Institute e da Université de Genève propuseram uma nova abordagem para modelos autoregressivos, chamada σ-GPTs (Sigma-GPTs). Este avanço pode representar uma mudança significativa na maneira como os modelos de linguagem, como o GPT, são treinados e geram texto. Vamos explorar como essa nova abordagem pode trazer melhorias aos modelos GPT e outros modelos de linguagem de larga escala (LLM).
O Problema com a Abordagem Tradicional
Modelos de linguagem como o GPT geralmente seguem uma ordem fixa ao gerar sequências de texto, geralmente da esquerda para a direita. Esse método tem suas limitações, uma vez que cada token subsequente depende estritamente dos tokens anteriores. Isso não só limita a flexibilidade do modelo, como também pode tornar o processo de geração de texto lento e ineficiente.
A Inovação dos σ-GPTs
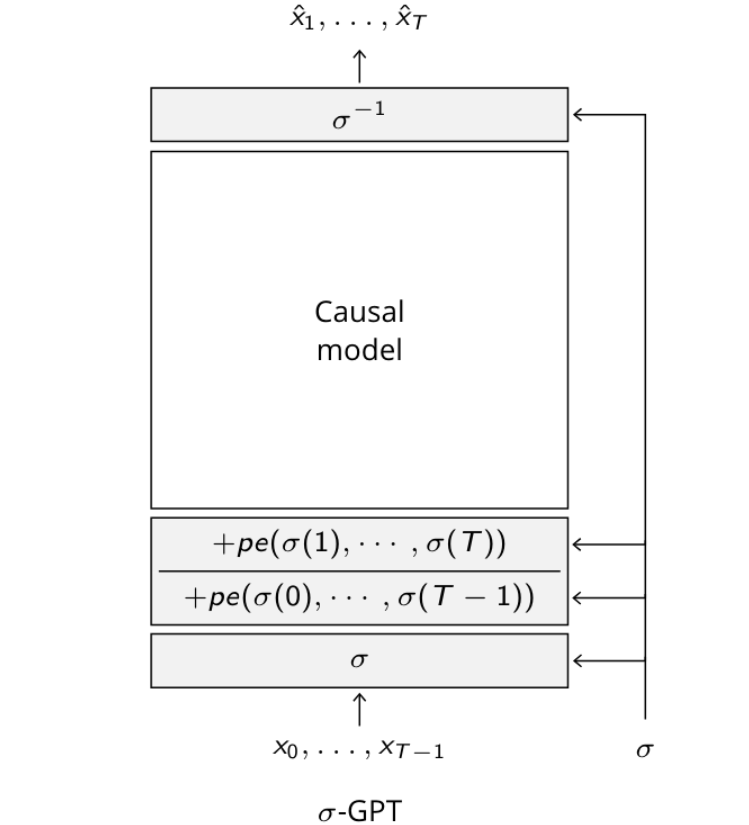
A principal inovação dos σ-GPTs é a introdução de uma "permutação embaralhada" dos tokens de entrada durante o treinamento, acompanhada de codificações posicionais duplas. Essencialmente, isso significa que, ao invés de seguir uma ordem fixa, o modelo pode prever tokens em qualquer ordem aleatória, permitindo uma maior flexibilidade e eficiência.
GPTs are generating sequences in a left-to-right order. Is there another way?
— Arnaud Pannatier (@ArnaudPannatier) June 7, 2024
With @francoisfleuret and @evanncourdier, in partnership with @SkysoftATM, we developed σ-GPT, capable of generating sequences in any order chosen dynamically at inference time.
1/6 pic.twitter.com/smoJ59MpFY
Codificações Posicionais Duplas
- Cada token recebe duas codificações posicionais: uma referente à sua posição atual e outra à posição do próximo token a ser previsto. Isso permite que o modelo compreenda e processe a sequência em qualquer ordem.
Estimativa de Densidade Condicional e Preenchimento
- A abordagem σ-GPT permite que o modelo faça estimativas de probabilidades condicionais para todos os tokens faltantes de uma vez. Isso significa que o modelo pode prever múltiplos tokens em paralelo, melhorando a velocidade de geração de texto.
- Além disso, suporta naturalmente o preenchimento de lacunas em sequências, onde partes conhecidas do texto são usadas para gerar as partes faltantes de maneira coerente.
Amostragem por Rejeição (Burst Sampling)
- Ao invés de gerar tokens sequencialmente, σ-GPTs podem gerar vários tokens simultaneamente e depois rejeitar combinações incompatíveis. Isso resulta em uma geração de textos consideravelmente mais rápida.
Resultados Promissores
Em uma série de testes, essa nova abordagem mostrou resultados promissores em diversas áreas:
- Modelo de Linguagem: σ-GPTs demonstraram alcançar desempenho semelhante ou melhor comparado aos modelos autoregressivos tradicionais quando treinados com um esquema de currículo que começa com sequências ordenadas e progride para sequências aleatórias.
- Solução de Caminhos e Predição de Taxa Vertical de Aeronaves: A abordagem reduziu significativamente o número de passos necessários para a geração, mantendo ou melhorando a qualidade.
Comentários da Comunidade HackerNews
A comunidade HackerNews também reagiu positivamente aos σ-GPTs.
Um usuário destacou que essa metodologia permite ao modelo preencher lacunas em paralelo e calcular densidades condicionais para tokens ausentes em paralelo, o que é uma melhoria significativa em relação às abordagens tradicionais.
Outro comentário mencionou a aplicação potencial dessa técnica em modelos de imagem, sugerindo a geração e aumento de resolução de imagens de maneira eficiente.
Conclusão
A abordagem σ-GPT apresenta uma forma inovadora de melhorar os modelos GPT e outros LLMs, oferecendo maior flexibilidade, eficiência e capacidade de geração paralela. Com base nos resultados e na recepção positiva da comunidade, é provável que vejamos uma adoção crescente dessa técnica em futuros desenvolvimentos de modelos de linguagem e outras aplicações de IA.
Essa nova era de modelos autoregressivos pode transformar significativamente as capacidades de geração de texto e outras tarefas envolvendo sequências, trazendo avanços tanto em termos de desempenho quanto de eficiência.
Esta nova abordagem ilustra como pequenas modificações na arquitetura e no treinamento de modelos de IA podem levar a grandes avanços tecnológicos. A inovação contínua nesses campos é vital para empurrar os limites do que é possível na inteligência artificial.



